Apache HTTP Server Version 2.3

Apache HTTP Server Version 2.3

This document discusses some of the technical details of mod_rewrite and URL matching.

The Apache HTTP Server handles requests in several phases. At each of these phases, one or more modules may be called upon to handle that portion of the request lifecycle. Phases include things like URL-to-filename translation, authentication, authorization, content, and logging. (This is not an exhaustive list.)
mod_rewrite acts in two of these phases (or "hooks", as they are often called) to influence how URLs may be rewritten.
First, it uses the URL-to-filename translation hook, which occurs
after the HTTP request has been read, but before any authorization
starts. Secondly, it uses the Fixup hook, which is after the
authorization phases, and after per-directory configuration files
(.htaccess files) have been read, but before the
content handler is called.
So, after a request comes in and a corresponding server or
virtual host has been determined, the rewriting engine starts
processing any mod_rewrite directives appearing in the
per-server configuration. (i.e., in the main server configuration file
and <Virtualhost>
sections.) This happens in the URL-to-filename phase.
A few steps later, once the final data directories have been found,
the per-directory configuration directives (.htaccess
files and <Directory> blocks) are applied. This
happens in the Fixup phase.
In each of these cases, mod_rewrite rewrites the
REQUEST_URI either to a new URL, or to a filename.
In per-directory context (i.e., within .htaccess files
and Directory blocks), these rules are being applied
after a URL has already been translated to a filename. Because of
this, mod_rewrite temporarily translates the filename back into a URL,
by stripping off directory path before appling the rules. (See the
RewriteBase directive to
see how you can further manipulate how this is handled.) Then, a new
internal subrequest is issued with the new URL. This restarts
processing of the API phases.
Because of this further manipulation of the URL in per-directory context, you'll need to take care to craft your rewrite rules differently in that context. In particular, remember that the leading directory path will be stripped off of the URL that your rewrite rules will see. Consider the examples below for further clarification.
| Location of rule | Rule |
|---|---|
| VirtualHost section | RewriteRule ^/images/(.+)\.jpg /images/$1.gif |
| .htaccess file in document root | RewriteRule ^images/(.+)\.jpg images/$1.gif |
| .htaccess file in images directory | RewriteRule ^(.+)\.jpg $1.gif |
For even more insight into how mod_rewrite manipulates URLs in different contexts, you should consult the log entries made during rewriting.
Now when mod_rewrite is triggered in these two API phases, it reads the configured rulesets from its configuration structure (which itself was either created on startup for per-server context or during the directory walk of the Apache kernel for per-directory context). Then the URL rewriting engine is started with the contained ruleset (one or more rules together with their conditions). The operation of the URL rewriting engine itself is exactly the same for both configuration contexts. Only the final result processing is different.
The order of rules in the ruleset is important because the
rewriting engine processes them in a special (and not very
obvious) order. The rule is this: The rewriting engine loops
through the ruleset rule by rule (RewriteRule directives) and
when a particular rule matches it optionally loops through
existing corresponding conditions (RewriteCond
directives). For historical reasons the conditions are given
first, and so the control flow is a little bit long-winded. See
Figure 1 for more details.
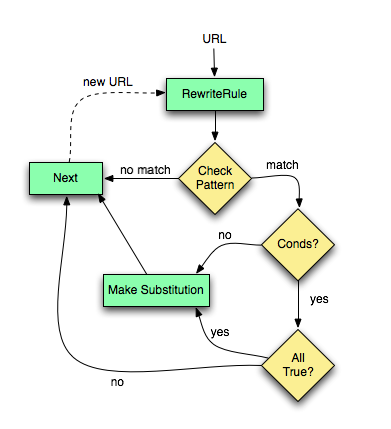
Figure 1:The control flow through the rewriting ruleset
As you can see, first the URL is matched against the Pattern of each rule. When it fails mod_rewrite immediately stops processing this rule and continues with the next rule. If the Pattern matches, mod_rewrite looks for corresponding rule conditions. If none are present, it just substitutes the URL with a new value which is constructed from the string Substitution and goes on with its rule-looping. But if conditions exist, it starts an inner loop for processing them in the order that they are listed. For conditions the logic is different: we don't match a pattern against the current URL. Instead we first create a string TestString by expanding variables, back-references, map lookups, etc. and then we try to match CondPattern against it. If the pattern doesn't match, the complete set of conditions and the corresponding rule fails. If the pattern matches, then the next condition is processed until no more conditions are available. If all conditions match, processing is continued with the substitution of the URL with Substitution.
