Serveur Apache HTTP Version 2.3

Serveur Apache HTTP Version 2.3

Ce document passe en revue certains détails techniques à propos du module mod_rewrite et de la mise en correspondance des URLs

Le fonctionnement interne de ce module est très complexe, mais il est nécessaire de l'expliquer, même à l'utilisateur "standard", afin d'éviter les erreurs courantes et de pouvoir exploiter toutes ses fonctionnalités.
Il faut tout d'abord bien comprendre que le traitement d'une
requête HTTP par Apache s'effectue en plusieurs phases. L'API
d'Apache fournit un point d'accroche (hook) pour chacune de ces
phases. Mod_rewrite utilise deux de ces hooks : le hook de
conversion des URLs en noms de fichiers qui est utilisé quand la
requête HTTP a été lue mais avant le démarrage de tout processus
d'autorisation, et le hook "Fixup" qui est déclenché après les
phases d'autorisation et après la lecture des fichiers de
configuration niveau répertoire (.htaccess), mais
avant que le gestionnaire de contenu soit activé.
Donc, lorsqu'une requête arrive et quand Apache a déterminé le serveur correspondant (ou le serveur virtuel), le moteur de réécriture commence le traitement de toutes les directives de mod_rewrite de la configuration du serveur principal dans la phase de conversion URL vers nom de fichier. Une fois ces étapes franchies, lorsque les repertoires de données finaux ont été trouvés, les directives de configuration de mod_rewrite au niveau répertoire sont éxécutées dans la phase Fixup. Dans les deux cas, mod_rewrite réécrit les URLs soit en nouvelles URLs, soit en noms de fichiers, bien que la distinction entre les deux ne soit pas évidente. Cette utilisation de l'API n'était pas sensée s'opérer de cette manière lorsque l'API fut conçue, mais depuis Apache 1.x, c'est le seul mode opératoire possible pour mod_rewrite. Afin de rendre les choses plus claires, souvenez-vous de ces deux points :
.htaccess, bien que ces derniers
soient traités bien longtemps après que les URLs n'aient été
traduites en noms de fichiers. Les choses doivent se dérouler
ainsi car les fichiers .htaccess résident dans le
système de fichiers, et le traitement a déjà atteint
cette étape. Autrement dit, en accord avec les phases de
l'API, à ce point du traitement, il est trop tard pour
effectuer des manipulations d'URLs. Pour résoudre ce problème
d'antériorité, mod_rewrite utilise une astuce : pour effectuer
une manipulation URL/nom de fichier dans un contexte de
répertoire, mod_rewrite réécrit tout d'abord le nom de fichier
en son URL d'origine (ce qui est normalement impossible, mais
voir ci-dessous l'astuce utilisée par la directive
RewriteBase pour y parvenir), puis
initialise une nouvelle sous-requête interne avec la nouvelle
URL ; ce qui a pour effet de redémarrer le processus des
phases de l'API.
Encore une fois, mod_rewrite fait tout ce qui est en son pouvoir pour rendre la complexité de cette étape complètement transparente à l'utilisateur, mais vous devez garder ceci à l'esprit : alors que les manipulations d'URLs dans le contexte du serveur sont vraiment rapides et efficaces, les réécritures dans un contexte de répertoire sont lentes et inefficaces à cause du problème d'antériorité précité. Cependant, c'est la seule manière dont mod_rewrite peut proposer des manipulations d'URLs (limitées à une branche du système de fichiers) à l'utilisateur standard.
Ne perdez pas de vue ces deux points!
Maintenant, quand mod_rewrite se lance dans ces deux phases de l'API, il lit le jeu de règles configurées depuis la structure contenant sa configuration (qui a été elle-même créée soit au démarrage d'Apache pour le contexte du serveur, soit lors du parcours des répertoires par le noyau d'Apache pour le contexte de répertoire). Puis le moteur de réécriture est démarré avec le jeu de règles contenu (une ou plusieurs règles associées à leurs conditions). En lui-même, le mode opératoire du moteur de réécriture d'URLs est exactement le même dans les deux contextes de configuration. Seul le traitement du résultat final diffère.
L'ordre dans lequel les règles sont définies est important car
le moteur de réécriture les traite selon une chronologie
particulière (et pas très évidente). Le principe est le suivant :
le moteur de réécriture traite les règles (les directives RewriteRule) les unes
à la suite des autres, et lorsqu'une règle s'applique, il parcourt
les éventuelles conditions (directives
RewriteConddirectives) associées.
Pour des raisons historiques, les
conditions précèdent les règles, si bien que le déroulement du
contrôle est un peu compliqué. Voir la figure 1 pour plus de
détails.
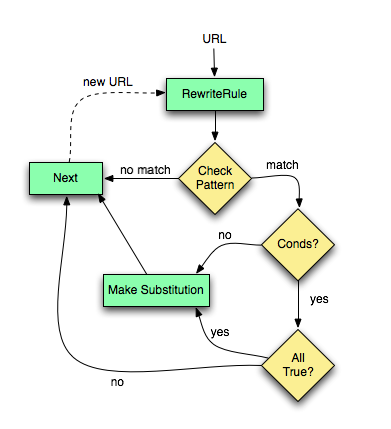
Figure 1:Déroulement du contrôle à travers le jeu de
règles de réécriture
Comme vous pouvez le voir, l'URL est tout d'abord comparée au Modèle de chaque règle. Lorsqu'une règle ne s'applique pas, mod_rewrite stoppe immédiatement le traitement de cette règle et passe à la règle suivante. Si l'URL correspond au Modèle, mod_rewrite recherche la présence de conditions correspondantes. S'il n'y en a pas, mod_rewrite remplace simplement l'URL par une chaîne élaborée à partir de la chaîne de Substitution, puis passe à la règle suivante. Si des conditions sont présentes, mod_rewrite lance un bouclage secondaire afin de les traiter selon l'ordre dans lequel elles sont définies. La logique de traitement des conditions est différente : on ne compare pas l'URL à un modèle. Une chaîne de test TestString est tout d'abord élaborée en développant des variables, des références arrières, des recherches dans des tables de correspondances, etc..., puis cette chaîne de test est comparée au modèle de condition CondPattern. Si le modèle ne correspond pas, les autres conditions du jeu ne sont pas examinées et la règle correspondante ne s'applique pas. Si le modèle correspond, la condition suivante est examinée et ainsi de suite jusqu'à la dernière condition. Si toutes les conditions sont satisfaites, le traitement de la règle en cours se poursuit avec le remplacement de l'URL par la chaîne de Substitution.
